Maximizing Performance and Accuracy with Vector Embeddings and LLMs

Large language models (LLMs), such as ChatGPT, are incredibly powerful. However, due to their vast training data, they can provide inaccurate information with confidence, making them unsuitable for many business applications that require highly accurate answers. To improve their accuracy, we need to provide them with the right context. But with so much unstructured text data available, how can we possibly provide the right context?
The answer that ChatGPT gives in the picture above is correct, but it lacks certain details. If you provide a paragraph or two about the thing you are asking, ChatGPT can provide a much more concise answer and is less prone to providing false information.
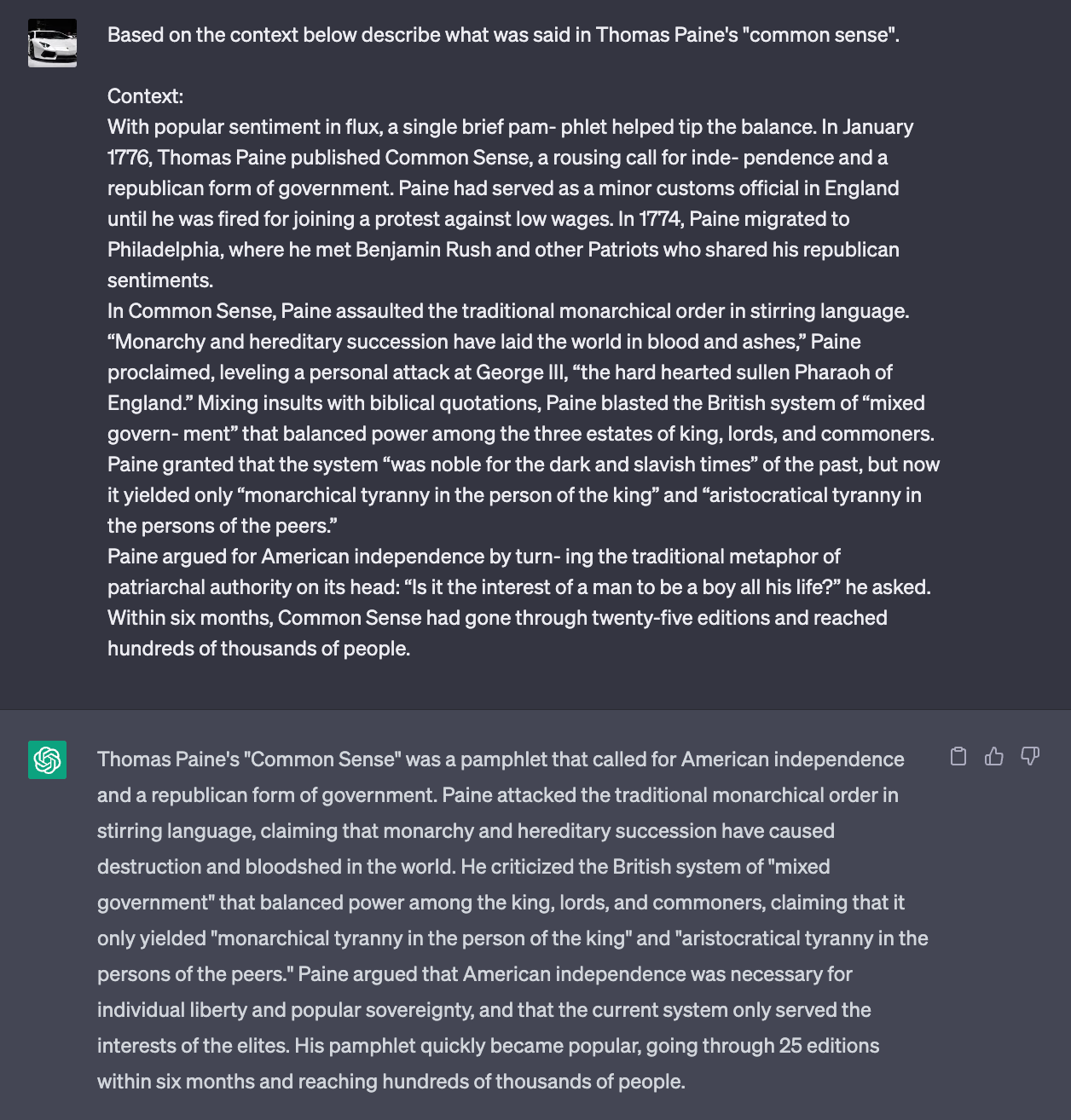
The answer provided above comes directly from the context provided and is much more detailed than the generic answer it came up with earlier. By providing context, you can also get personalized answers without having to fine-tune the model by training it on your data.
So you've seen that if you give ChatGPT some relevant information, it can answer your questions with more detail and greater accuracy. But isn't there a limit as to how many words I can provide as context? How am I supposed to provide context for hundreds of pages of text scattered across multiple sources?
Enter Embeddings....
Embeddings are a way to represent unstructured data such as text or images for computers to understand. Traditionally, computers have only been able to understand numbers (binary). Even machine learning systems that work with text convert the text to a number to represent different categorical values. The technology behind ChatGPT is no different and can only process numbers, not text.

The way a sentence gets converted into a series of numbers is somewhat magical. When a sentence is passed into an LLM, the model extracts features from the text, converting them into a series of numbers called embeddings. These numbers may look random to us, but they hold significant meaning for computers.
Our brains automatically understand that sentences and paragraphs are related to each other, and even if the paragraphs are not presented in logical order, we can still extract their meaning. LLMs, on the other hand, find this task challenging. That's where embeddings come in handy.

These embeddings are commonly referred to as vectors. By converting each paragraph into an embedding, we can use vector arithmetic to find similar paragraphs. I won't get into the math behind this, but the general idea is to calculate the distance between all of the vectors. There are many common distance measurements people use such as:
- Cosine Distance
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
Cosine distance or cosine similarity, as its commonly referred to, tends to be popular when working with embeddings. Regardless of which distance measurement you use, the key thing to understand is that the shorter the distance between two vectors the more similar their text will be. Conversely, vectors that have a large distance represent text that is dissimilar to each other.
By using this concept when can find the text that is most similar to the user query for ChatGPT to answer. The user's query gets converted into an embedding and then you can use vector similarity to find out which embeddings are related based on a distance measurement. The text corresponding to the embeddings serves as our context which is what we were looking for in the first place.


With vector embeddings, we can store large amounts of text data and only find the most similar pieces of text to the user query. This way, our LLMs can give us accurate answers about our specific data, rather than just regurgitating random data the model was initially trained on. It's important to remember to store both the original text and the vector embedding, as the vector embeddings cannot be turned back into text.
In summary, embeddings provide a way for LLMs to understand unstructured data like text by converting it into a series of numbers. By using vector arithmetic to find similar paragraphs, we can provide the right context to our LLMs, resulting in highly accurate answers that are specific to our data.
Member discussion